Optimizing your C++ code for molecular dynamics
While working with the molecular dynamics project in FYS4460 I decided to learn more about how to optimize my C++ code for performance. As always, I follow Donald Knuth’s famous quote as a guideline to optimization:
“We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil”^[2]^
And this has proved to be as true as ever in my efforts to optimize my code. There are a bunch of things that I have tried that didn’t turn out to be as effective as I had thought, and some other that I would never think could be so important. I’ve listed most of these in this post so you too may learn from my experience. They are all listed in the order from most useful to most wasteful:
Benchmark!
Before doing any “optimization”, benchmark your code by using a timer (MPI has a timer in their library, as does Boost::MPI). Otherwise you might be optimizing and rewrite already working code for no good reason. You should always measure and see if your optimizations are good for anything. If they are not, you should consider leaving things as they are for the sake of readability or style.
Analyze your code using a tool such as Qt Creator (and Valgrind)
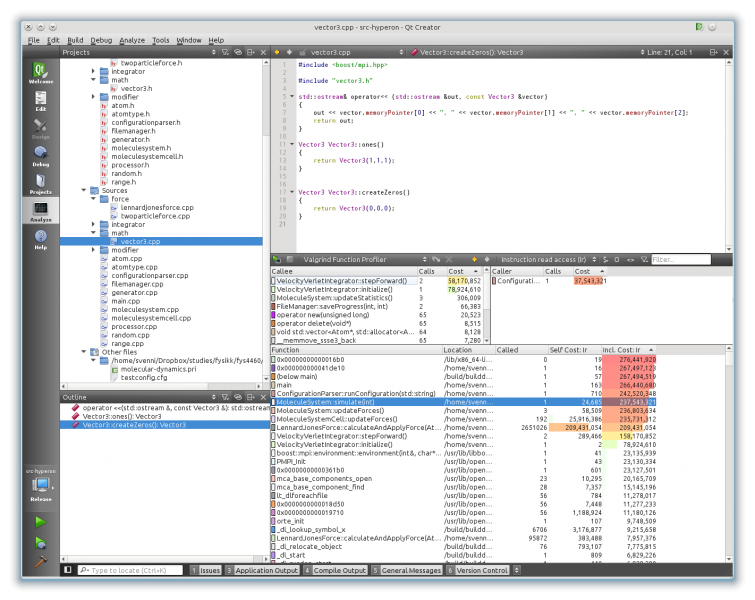
Qt Creator has a really neat visualization tool for the Valgrind profiler. This visualization is very helpful to figure out what parts of your application is actually wasting time.
[ ](https://dragly.org/wp-content/uploads/2013/03/qt-valgrind.png)
Qt’s Valgrind visualization is very neat to see what parts of your code
that are spending the most time.[/caption]
](https://dragly.org/wp-content/uploads/2013/03/qt-valgrind.png)
Qt’s Valgrind visualization is very neat to see what parts of your code
that are spending the most time.[/caption]
Here you may see the number of instruction calls each functions makes use of. This helps greatly in pinpointing the bottlenecks of you code.
You can read more about Qt and Valgrind on their webpages.
Use const references (or pointers) whenever possible
Whenever you are declaring a function or a variable, you should most likely use const references all over the place. References keeps your code from making unnecessary copies while the const keeps you from making changes to things that should be constant. Just don’t return references of temporary objects!
In practice you should change your getter function declarations (and implementations) from
Vector3 Atom::position();
to
const Vector3& Atom::position();
But only do this when the object you return is a class member. Such as the position is for the Atom. If you return av temporary you must by all means return a copy. However, you may let the parameter be a reference.
Vector3 Atom::vectorTo(const Atom& otherAtom) {
Vector3 vector = otherAtom.position() - this->position();
return vector;
}
Note the ampersand (&) which tells the compiler that you wish to return a reference declaration. Whenever this is left out, the compiler will think that you want to make a copy of the object, which can be very expensive performance wise.
If you are using pointers, you don’t have to worry about this. You should go back to worrying about allocating memory instead.
Write components of 3D vectors explicitly in your force calculation
The following code may look nasty in comparison to for instance using a vector class with overloaded + and = operators, but it is much faster:
double x;
double y;
double z;
x = atom2->position()(0) + atom2Offset(0) - atom1->position()(0);
y = atom2->position()(1) + atom2Offset(1) - atom1->position()(1);
z = atom2->position()(2) + atom2Offset(2) - atom1->position()(2);
rSquared = x*x + y*y + z*z;
This is generally true, but more so if you are using a general vector class and not an optimized 3D vector class. Optimized 3D vector classes will be only a bit faster.
Inline your much-used getters and setters
If you are using getters and setters like
const Vector3& Atom::position() const {
return m_position;
}
you may want to inline these in the header file. Ideally you should declare the header as usual and put the implementation with the inline keyword in the same header file:
class Atom
{
public:
inline const Vector3 &position() const;
protected:
Vector3 m_position;
}
inline const Vector3 &Atom::position() const
{
return m_position;
}
Did you notice the extra const at the end of the declaration? This is just good style telling the compiler that this function will not write to the Atom object, only read from it. Again, this is good style, but not necessary.
Use double arrays instead of classes to store positions and forces
I’m not doing this myself, but after some intense optimization testing i found that for the Lennard-Jones force, the code runs in about 67 % of the original time by storing the positions and forces in their own continuous-memory arrays rather than in Atom objects.
This is optimal because (for my code at least) it caused the processor to keep data in the CPU cache over longer time, which is faster than having to fetch new data from RAM. The reason is likely that it can prefetch the position data more easily when it is stored sequentially rather than together with other data in the Atom object.
This may differ greatly from architecture to architecture, so I skipped actually implementing this myself. The code became so much harder to maintain with this optimization built in that I eventually left it out. In addition, I have no idea how it would fare with 3- or 6-particle forces which are yet to be implemented.
If you store everything in double arrays already I would also advice you to consider storing it in static-size memory on the stack rather than allocating the memory dynamically. I hear that this is also supposed to improve performance.